前言
什么是SEO:SEO 是 Search Engine Optimization 的缩写,即搜索引擎优化。它是一种通过调整网站的内容、结构、外部链接等方面的优化手段,来提高网站在搜索引擎自然/免费搜索结果中的排名和可见度的过程
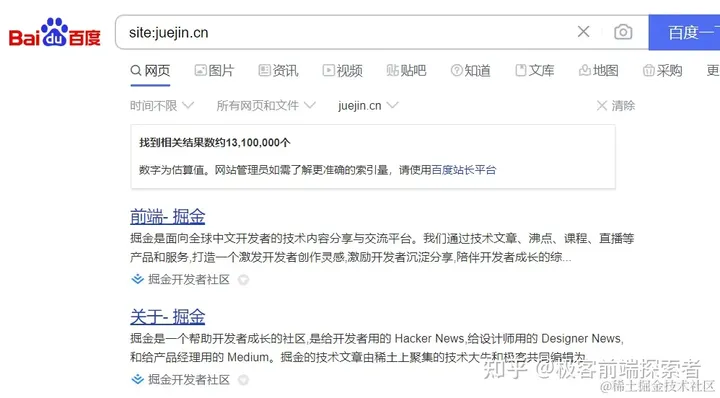
例如在站长工具:seo.chinaz.com/,中查看掘金的收录情况
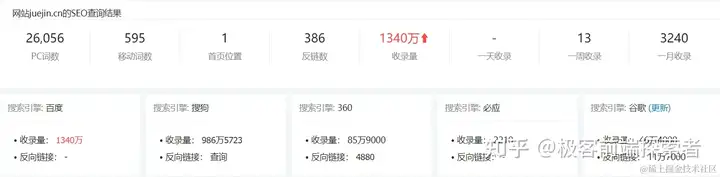
从图中可以看到掘金的收录数还是非常不错的 统计公报 或者在各搜索框内使用“site: 域名”的方式,例如:site:juejin.cn获取收录数
一、TDK
TDK是Title(标题)、Description(描述)和 Keywords(关键词)的缩写,是网站SEO的关键
1. title
Title:页面标题,是搜索引擎最重视的元素之一,它直接决定了页面在搜索结果中的标题显示
<title>标题</title>
注意点:
避免过于冗长,大多数搜索引擎和浏览器中能完全显示的长度为 60-70 个字符,超出则会被截断
冗长的标题可能导致关键词密度降低,从而影响搜索引擎对网页内容的判断
2. description
description:页面描述,内容通常会被用作页面的摘要信息展示
<metaname="description"content="网站的描述">
注意点:
内容不宜过短,作为摘要信息展示的时候如果一行都显示不全,不利于吸引用户点击
内容最好控制在160 个字符以内
3. keywords
keywords :页面关键词
因为滥用等原因,大多数主流搜索引擎已经大幅降低了 keywords 元标签对网页排名的影响
<metaname="Keywords"content="网站的关键词">
注意点:
不同页面的关键词应该尽量不重复,避免关键词相互竞争
关键词的数量应控制在4-8 个,过多可能会被搜索引擎认为是关键词堆砌,影响SEO效果
提示:对于不同页面,可设置不同的TDK,来增加关键词的收录量
二、OG 协议
Open Graph 协议是由 Facebook 提出的一种元数据标准,它允许页面成为丰富的社交对象。通过在网页中添加特定的 Open Graph 协议,可以帮助提供更丰富的预览信息。
常见的 Open Graph 标签包括:
<metaproperty="og:title"content="页面标题"><metaproperty="og:description"content="页面描述"><metaproperty="og:image"content="图片URL"><metaproperty="og:url"content="页面URL"><metaproperty="og:type"content="网页类型,如website,article"><metaproperty="og:release_date"content="定义网页内容的发布时间">
例如在bing搜索掘金,看到掘金的最新相关信息
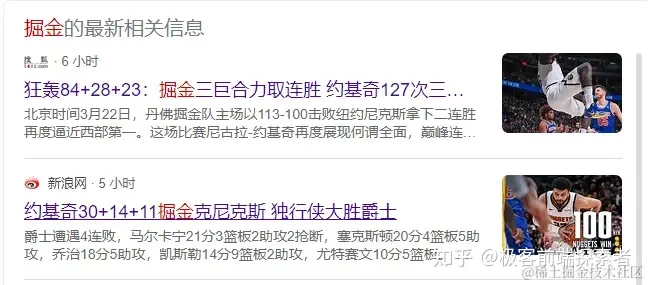
点开第一条搜狐的,看title头部,发现使用的og协议如下
<metaproperty="og:type"content="news"><metaproperty="og:image"content="https://q3.itc.cn/q_70/images03/20240322/1d853e1d019a4739b5f882e5e44699f3.png"><metaproperty="og:url"content="www.sohu.com/a/766002411_343291"><metaproperty="og:release_date"content="2024-03-2211:32"><metaproperty="og:description"content="这场比赛尼古拉-约基奇再度展现何谓全面,巅峰连庄MVP是真的厉害,锡伯杜已经制订了三人轮番消耗约基奇的策略依旧没用,约老师还是能带动队友。波特开场是3中3拿8分,半场是6中6+三分1中1拿15分4篮板;贾马…"><metaproperty="og:title"content="狂轰84+28+23:掘金三巨合力取连胜约基奇127次三双冲西部第一_篮板_助攻_波特">
其中og:image的图片链接,就是截图中右侧的图片
三、HTML 语义化
HTML语义化主要作用有以下几点:
方便其他设备进行解析,例如盲人阅读器
有利于SEO,搜索引擎更容易理解语义化页面的内容结构和主题
便于团队开发和维护,语义化更具有可读性
1. 标题标签
HTML 中共有 6 种 h 标签,分别是h1、h2、h3、h4、h5 和 h6。这些标签表示文字的大小和重要性,h1 最大最重要,h6 最小最次要。
相比其他标签,h 标签在页面中的权重非常高,所以使用时要注意不要滥用。
例如,h1 通常用来写网页的主标题,应该与网页 title 标签的内容保持一致,并在页面中展示。每个页面最好只有一个 h1 标签。h2 可用来写次级标题,h3-h6 依次用于更细分的标题
2. 强调标签
strong:标签一方面是强调,增加了权重;另一方面也能字体加粗,增强视觉效果
em:标签一方面是强调,增加了权重;另一方面也能字体变为斜体,增强视觉效果
强调标签权重虽比h标签低,但也比其他标签权重高
3. 超链接标签
1. a 标签分为“内链”和“外链”
内链:从自己网站的一个页面指向另外一个页面。通过内链让网站内部形成网状结构,让蜘蛛的广度和深度达到最大化
外链:在别的网站导入自己网站的链接。通过外链提升网站权重,提高网站流量。
2. a 标签的两个属性
带有rel=nofollow 属性的链接会告诉搜索引擎忽略这个链接。阻止搜索引擎对该页面进行追踪。从而避免权重分散
js复制代码<arel="nofollow"href="http://www.baidu.com/">百度</a>
external字面意思是“外部的”,a 标签加上这个属性代表这个链接是外部链接,非本站链接,点击时会在新窗口中打开,它和target="_blank"效果一样。external 可以告诉搜索引擎这是一个外部链接,非本站的链接
js复制代码<arel="external"href="http://www.baidu.com/">百度</a>
4. 图片标签
: 图像标签的 alt 属性有助于图像 SEO,并在网络故障时,代替图片显示
5. 段落标签
p 标签虽然权重较低,但作为页面基础内容结构很重要。页面中用长文字描述的内容,都可以使用p标签代替原先的div标签
6. 列表标签
ul:标签表示无序列表
ol:标签表示有序列表
li:标签表示列表的一项
搜索引擎能够通过这些标签更好地理解信息的层次结构和关联性,从而更准确地评估网页的内容和价值
7. 布局标签
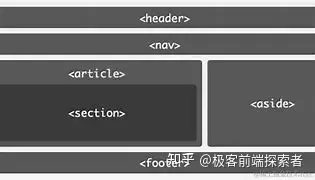
header:定义页眉,通常包含网站标志、主导航、搜索框等
nav:定义导航
article:定义独立的、完整的内容块,如博客文章、新闻报道等
section:定义页面上的独立的、有语义的内容块,如章节
aside:定义侧边栏
footer:定义页脚,通常包含版权信息、联系方式、备案信息等
四、sitemap 站点地图
sitemap 站点地图一般是xml格式的文件,用于帮助搜索引擎更好地发现和抓取网站上的所有页面,并提供页面优先级和更新频率的信息,帮助搜索引擎更好地分配抓取资源
sitemap.xml 内容格式如下:
js复制代码<urlsetxmlns="http://www.sitemaps.org/schemas/sitemap/0.9">
<url>
<loc>https://acme.com</loc><lastmod>2023-04-06T15:02:24.021Z</lastmod>
<changefreq>yearly</changefreq>
<priority>1</priority>
</url>
<url>
<loc>https://acme.com/about</loc><lastmod>2023-04-06T15:02:24.021Z</lastmod>
<changefreq>monthly</changefreq>
<priority>0.8</priority>
</url>
</urlset>
loc:页面地址
lastmod:内容最后修改时间
changefreq:预计更新频率
priority:页面相对于其他页面优先级,它的值范围是0.0到1.0,其中1.0表示最高优先级
sitemap.xml 一般放在网站的根目录下,可以通过“域名+/sitemap.xml”的形式直接访问到。但每个 sitemap文件最多包含 50,000 个 URL 标签,如果网站页面超过 50,000 个,则应该将 Sitemap 文件拆分成多个。
例如在根目录下新建sitemap.xml,并新建sitemap文件夹用于统一管理页面的站点地图信息
js复制代码//sitemap.xml<sitemapindexxmlns="http://www.sitemaps.org/schemas/sitemap/0.9">
<sitemap>
<loc>https://example.com/sitemap/sitemap1.xml</loc><lastmod>2023-04-01</lastmod>
</sitemap>
<sitemap>
<loc>https://example.com/sitemap/sitemap2.xml</loc><lastmod>2023-04-15</lastmod>
</sitemap></sitemapindex>
<sitemapindex>: 用于包含多个 sitemap文件的索引。
如果sitemap.xml没有放在根目录,即不能通过“域名+/sitemap.xml”的形式直接访问到,需在 robots.txt 中指明Sitemap位置,否则搜索引擎可能无法找到
五、 robots 文件
robots.txt 文件是一个网站用来告诉搜索引擎机器人(又称爬虫或蜘蛛)应该如何抓取和索引该网站的一种标准
robots.txt 文件需放置在网站的根目录下,以“域名+/robots.txt”的形式直接访问到
js复制代码User-Agent:*Disallow:/private/Sitemap:https://acme.com/sitemap.xml
User-agent: 该项的值用于描述搜索引擎蜘蛛的名字。如果该项的值设为*,则该协议对任何机器人均有效
Disallow:这条指令明确地告诉爬虫不要访问 /private/ 路径及其下的所有内容。这是 robots.txt 文件的核心功能之一,用于保护网站中不希望被搜索引擎索引的页面或内容。
Sitemap:提供网站 sitemap 的 URL 地址,帮助搜索引擎爬虫更有效地发现和索引这些页面
六、各搜索引擎提交站点收录
除了robots.txt + sitemap.xml 方式增加网址被收录的可能性外,还可以在各搜索引擎站长平台手动提交网址,以缩短爬虫发现网站链接时间,加快爬虫抓取速度
百度:ziyuan.baidu.com/
谷歌:developers.google.com/search?hl=z…
搜狗:zhanzhang.sogou.com/
360:zhanzhang.so.com/
必应:www.bing.com/webmasters/…
七、服务端渲染
爬虫只能抓取到网页的静态源代码,而无法执行其中的JavaScript脚本。当网站采用Vue或React构建SPA项目时,页面上的大部分DOM元素实际上是在客户端通过JavaScript动态生成的。这意味着爬虫能够直接抓取和分析的内容会大幅减少
熟悉vue的,可使用Nuxt
熟悉React的,可使用Next。对Next感兴趣的,可参考我的另一篇文章给上市公司从0到1搭建Next.js14项目
爬虫除了不会抓取JavaScript脚本的内容,也不会抓取iframe中的内容,因此项目中少用iframe
八、网址规范化
例如,一个页面可能有多个 URL 地址,比如:
https://example.com/article.htmlhttps://example.com/articlehttps://www.example.com/article
这些 URL 指向同一个页面内容。但是,我们应该指定其中一个作为该页面的规范化 URL
在每个非规范版本的 HTML 网页的<head>部分中,添加一个 rel="canonical" 链接来进行指定规范网址
<linkrel="canonical"href="https://www.example.com/article"/>
九、网站性能
网站打开速度越快,识别效果越好,否则爬虫会认为该网站对用户不友好,降低爬取效率
来源:极客前端探索者